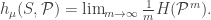Which text gives us more information – the full body of work of Shakespeare, or 884,647 random words written by 1000 monkeys?
To answer this, we talk with our good friend Alice, and ask her to send both of these texts to her close friend Bob. It should seem reasonable that the more information “dense” a text is, the harder it is to send it. Since the time of Shakespeare, we invented the internet over which we can only send messages over the simple 0\1 alphabet so Alice’s job is to translate the text to this 0\1 alphabet. If she manages to find a good translation with fewer 0\1 bits, the easier her job is. If the original text contained a lot of redundancy, namely many parts of the text don’t contain “new” information, then we expect Alice could shorten the message a lot. Conversely, the more information the message has, the harder it is to compress it.
So now, Alice needs to chose for each English letter  a word
a word  over
over  and then the message
and then the message 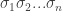 is coded to be
is coded to be  . This leaves us with the question of what is the best that we can hope to gain this way?
. This leaves us with the question of what is the best that we can hope to gain this way?
For simplicity, lets assume that the Englih alphabet only contains  . A simple coding is the mapping
. A simple coding is the mapping  , so for example we have
, so for example we have
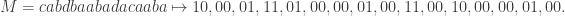
When Bob sees the word over (without the commas), he can decode it by dividing it to pairs of 0\1 and then decode each pair. In this case we needed  bits for a legth-
bits for a legth- message (and in this example, total of 32 bits). Can we do better than that?
message (and in this example, total of 32 bits). Can we do better than that?
Prefix free codes:
At this point Alice notes that she uses a lot of  ‘s and thinks that maybe she can use a shorter coding for , for example
‘s and thinks that maybe she can use a shorter coding for , for example  , and keep the rest of the letters with the same coding. The problem then is that when Bob sees
, and keep the rest of the letters with the same coding. The problem then is that when Bob sees  he doesn’t know if it belong to an or it is the beginning of
he doesn’t know if it belong to an or it is the beginning of  (which is mapped to 01). In order to help Bob decode the message, Alice decides to use a prefix free code – no coding of one letter is a prefix of a coding of another letter. This way, once Bob reads the coding of for some
(which is mapped to 01). In order to help Bob decode the message, Alice decides to use a prefix free code – no coding of one letter is a prefix of a coding of another letter. This way, once Bob reads the coding of for some 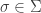 he knows that this coding must belong to and not part of a coding of a different letter. The best way to visualize such a code is using a binary tree, for example:
he knows that this coding must belong to and not part of a coding of a different letter. The best way to visualize such a code is using a binary tree, for example:

The coding of a letter is the string on the path leading from the root of the tree to the leaf labeled with . So in the tree above we have that  and
and  . Now the coding will be
. Now the coding will be

You should check that you can decode the coded message above back to the original message. Letting 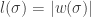 be the length of the coding of and
be the length of the coding of and 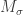 be the number of occurrences of in the message, we get that the length of the coded message is
be the number of occurrences of in the message, we get that the length of the coded message is  . In this example we have
. In this example we have

 ,
,
and therefore the number of bits used is  , which is less than the 32 bits in Alice’s previous attempt.
, which is less than the 32 bits in Alice’s previous attempt.
Before, we used exactly two bits per letter. How many do we have now? Well, the computation is simply  which in our example is
which in our example is  which is less than the 2 bits per letter in the previous coding. Note also that we can write this as
which is less than the 2 bits per letter in the previous coding. Note also that we can write this as
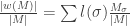 ,
,
where  is exactly the probability of seeing in a random place in
is exactly the probability of seeing in a random place in  which is independent of the coding that Alice chooses. In the example above we get
which is independent of the coding that Alice chooses. In the example above we get

 ,
,
 .
.
This let us compute the bits per letter directly from the coding scheme, instead of having to code the entire message and then count the number of bits there.
The best prefix code:
Can we do better than that by choosing a different coding? In the case above, the answer is no, but how can such a claim be proven? To do that, we first need to ask ourselves what conditions do the lengths 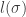 must satisfy for any given prefix code. Clearly, the lengths cannot be too small. For example, if
must satisfy for any given prefix code. Clearly, the lengths cannot be too small. For example, if  , than the tree must look like
, than the tree must look like

and in particular there is no room for other letters. Similarly, we cannot have 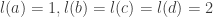 . To get some intuition – if all the leaves had height
. To get some intuition – if all the leaves had height  , then we would had at most
, then we would had at most  leaves. You should think of that as giving each leaf of height the weight
leaves. You should think of that as giving each leaf of height the weight  and asking that the total weight would be at most
and asking that the total weight would be at most  . The next claim shows that this is true even when the leaves have different heights.
. The next claim shows that this is true even when the leaves have different heights.
Claim: Let  be integers. Then there is a binary tree
be integers. Then there is a binary tree  with leaves
with leaves  at heights
at heights 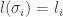 if and only if
if and only if 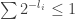 .
.
Proof: Assume first that all the 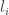 are equal to . In this case, the claim there is a binary tree with leaves at height if and only if
are equal to . In this case, the claim there is a binary tree with leaves at height if and only if 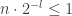 . The claim is now proved by noting that the maximum number of leaves of height in a binary tree is .
. The claim is now proved by noting that the maximum number of leaves of height in a binary tree is .
For the more general claim, we note that given a binary tree, we can always change a leaf of height to an internal node and give it two children leaves of height  .
.

Moreover, these two new leaves contribute the same weight as the original leaf, since
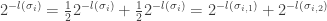 .
.
If we are now given a binary tree with leaves at heights 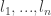 , then we can always split a leaf at height into two leaves of height
, then we can always split a leaf at height into two leaves of height  without changing the total weight. Doing this process several times until all the leaves are at the same height will show that their total weight must be smaller than 1, and therefore
without changing the total weight. Doing this process several times until all the leaves are at the same height will show that their total weight must be smaller than 1, and therefore 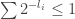 .
.
The other direction is proved similarly, and I will leave it as an exercise. 
Returning back to Alice’s problem, we want to minimize the length of the coded message  given the condition
given the condition 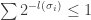 where the
where the  are positive integers. A minimization problem with integer coefficients can be quite hard (though this one is not too difficult), so we relax the problem and ask only that
are positive integers. A minimization problem with integer coefficients can be quite hard (though this one is not too difficult), so we relax the problem and ask only that 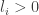 . A simple Lagrange multipliers argument will show that the best that we can hope for is when
. A simple Lagrange multipliers argument will show that the best that we can hope for is when  . Doing a little sanity check – note that if a letter appears many times in , then
. Doing a little sanity check – note that if a letter appears many times in , then  is going to be large and therefore is going to be small.
is going to be large and therefore is going to be small.
If the are all powers of  , then
, then  are all integers, so we solved the minimization problem with integer lengths as well – which is the case with our example above. Otherwise we can try to round the logarithms up or down to get an integer solution. In general, there is a way to find the best solution for such coding (with integer lengths!) which is called Huffman’s coding where the ideas there are very similar to the claim that we proved above.
are all integers, so we solved the minimization problem with integer lengths as well – which is the case with our example above. Otherwise we can try to round the logarithms up or down to get an integer solution. In general, there is a way to find the best solution for such coding (with integer lengths!) which is called Huffman’s coding where the ideas there are very similar to the claim that we proved above.
Considering the number of bits per letter leads us to the definition of entropy.
Definition: Let 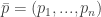 be a probability vector. The entropy of
be a probability vector. The entropy of  is then defined to be
is then defined to be  , where we take
, where we take 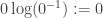 .
.
Thus, with this notation, the best bits per letter that we can hope for is  . In our example above, we have
. In our example above, we have  , so that the best bits per letter we can hope for is
, so that the best bits per letter we can hope for is

which is what we got in Alice’s second coding.
A single letter is not enough:
After enough time Alice decides that spending bits per letter is too much and she wonders if she can reduce it even further. The main idea in the previous coding is that if we have some information about the message (e.g. how many times each letter appears), then we can construct a coding that uses this information in order to get good bound on the bits per letter.
With this in mind, instead of looking on how many times each letter appears, we can consider instead how many times each pairs of letters appear in the message. For example, in the message  , the letters and appear each half of the time, so in a sense we don’t have any extra information. On the other hand, if we consider it as a word over
, the letters and appear each half of the time, so in a sense we don’t have any extra information. On the other hand, if we consider it as a word over  , then the number of times that we see
, then the number of times that we see  and
and  is
is  and . This is not uniform anymore, namely it gives us some information that we can work with.
and . This is not uniform anymore, namely it gives us some information that we can work with.
We can now use the same idea from before, just for pairs of letters. We choose a prefix code for the new alphabet  , i.e. lengths
, i.e. lengths  such that
such that 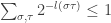 to get a coded message of length
to get a coded message of length 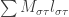 . Note that now
. Note that now  , so that the number of bit per letter is
, so that the number of bit per letter is

While it is not exactly clear from the formulas, this can only improve our bits per letter, since any coding that relies on one letter information can be done using two letters information. In particular, in our original example, this will reduce the  bits per letter to
bits per letter to  .
.
If we can do two letters, then we can also do three letters, and  letters, where the bits per letter is (up to integer rounding) at most
letters, where the bits per letter is (up to integer rounding) at most
 .
.
In a sense, we would like to take the limit of such codings, however we need to be careful. We ignored it up until now, but Alice also has to tell Bob how to encode her message, namely the map from words of length to their coding. If is relatively small compared to , then this extra information doesn’t add to much to the message that Alice sends. But if it is too large (e.g. 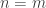 ), then this extra information is too large and changes the whole computation.
), then this extra information is too large and changes the whole computation.
Returning to our original question, the text of Shakespeare’s “A midsummer night’s dream” has 63 types of characters (so for the uniform coding you will need about 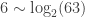 bits per letter, but if you compute the 1-letter entropy, you will get that you only need around 4.687 bits per letter. In particular, a uniform typing monkey (now sold in stores near you) will produce a text with more “information”, though probably useless information. While it is a bit counter intuitive, you can think of this as follows: If you already read 1000 words from Shakespeare, there is a good chance that you can guess the 1001 word, so it carries less information, while every word the monkey writes is a new surprise.
bits per letter, but if you compute the 1-letter entropy, you will get that you only need around 4.687 bits per letter. In particular, a uniform typing monkey (now sold in stores near you) will produce a text with more “information”, though probably useless information. While it is a bit counter intuitive, you can think of this as follows: If you already read 1000 words from Shakespeare, there is a good chance that you can guess the 1001 word, so it carries less information, while every word the monkey writes is a new surprise.
To infinity and beyond:
I will finish with a more advanced section which shows how the entropy definition so far leads to entropy definition for more general systems.
Up until now we had a single message and we used a preprocess to determine the probabilities of letters, pair of letters etc, in order to construct a good coding. Usually we will have a lot of messages to code and we want to think of them as coming from some “process” (for example, Shakespeare’s mind) and construct the code according to this process.
In order to formalize this notion we consider the space
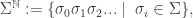
namely all the infinite (one sided) words over the finite alphabet  . The “process” is going to be a measure on this space, which basically tells us that we are more likely to see some (infinite) messages over others. For a finite word
. The “process” is going to be a measure on this space, which basically tells us that we are more likely to see some (infinite) messages over others. For a finite word  over and an integer
over and an integer  we will denote by
we will denote by  all the infinite words which contain the word beginning from the index . For example,
all the infinite words which contain the word beginning from the index . For example,  contain words which look like
contain words which look like  where
where  can be any letter from . We call such sets cylinders. The topology defined by these sets on
can be any letter from . We call such sets cylinders. The topology defined by these sets on 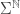 is exactly the product topology, though we will not use this fact here.
is exactly the product topology, though we will not use this fact here.
Let  be a measure on which assigns a measure to each of the cylinder sets. We think of this measure as the probability of seeing a certain finite subword in a message. For example, the probability that the message will start with is
be a measure on which assigns a measure to each of the cylinder sets. We think of this measure as the probability of seeing a certain finite subword in a message. For example, the probability that the message will start with is  . The probability to start with some letter and then
. The probability to start with some letter and then  is
is  , etc.
, etc.
Finally, if we have a lot of messages coming from the same source, we expect that the probability of seeing in the 100 place, is the same as seeing it in the 1000 place. There is no special reason why should appear more in the -th location than in the -th location for two indices  . The only caveat is maybe for the first few letters, but we will ignore this. To formalize this notion we define the shift left function
. The only caveat is maybe for the first few letters, but we will ignore this. To formalize this notion we define the shift left function 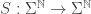 by
by 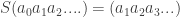 . The property above is then written as
. The property above is then written as 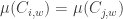 for any finite word and any two indices
for any finite word and any two indices 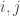 . More generally, it means that is shift invariant, namely
. More generally, it means that is shift invariant, namely 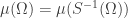 , where we note that
, where we note that 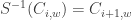 .
.
Because of this shift invariance , we should think of the probability of seeing some in the first  letters as the probability of seeing it in the first letter, namely . To get some intuition regarding this statement, let
letters as the probability of seeing it in the first letter, namely . To get some intuition regarding this statement, let  be the function defined by
be the function defined by 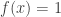 if the first letter is and zero otherwise, or in other words this is the characteristic function of
if the first letter is and zero otherwise, or in other words this is the characteristic function of 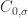 . Note that
. Note that  has as its k-th letter exactly if
has as its k-th letter exactly if 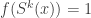 . Thus, the probability of seeing in the first letters is
. Thus, the probability of seeing in the first letters is  . If we are lucky, then this average is close to the integral of
. If we are lucky, then this average is close to the integral of  , namely
, namely 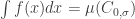 . This is indeed the case when is simple enough (ergodic), so we can use the measures
. This is indeed the case when is simple enough (ergodic), so we can use the measures  as our replacements for the
as our replacements for the  from before.
from before.
Thus, the first step entropy is going to be

Similarly, the step entropy is going to be
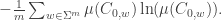
As we want a general definition, we can no longer use the “decomposition” of elements in our space into letters. For example, maybe we want to compress the messages using the ideas in the message, or any other way which doesn’t directly rely on their spelling. The abstract formulation is instead of looking on  which is just a finite partition of the space (since every message begin with some letter from ), we can instead look on a general partition
which is just a finite partition of the space (since every message begin with some letter from ), we can instead look on a general partition  where
where  . Then the first step entropy is defined by
. Then the first step entropy is defined by

How do we define the -step? Well, the message begins with  if it begins with and after one shift left the new message begins with
if it begins with and after one shift left the new message begins with  . In other words
. In other words  . Note that we only used our original partition and the shift map. In general, we define
. Note that we only used our original partition and the shift map. In general, we define  to be the partition with atoms of the form
to be the partition with atoms of the form  , and the -step entropy is
, and the -step entropy is
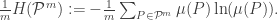
Finally, one can show that there is a limit to this entropies as  , so the final definition of the entropy of with respect to the shift action
, so the final definition of the entropy of with respect to the shift action  and the partition
and the partition  is
is