
1. Introduction
In this post we consider an interesting mathematical process which can be easily simulated by a computer, and generates interesting pictures. A video version of this post can be seen in here (for now in Hebrew).
Let 
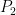

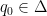



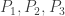
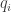



The “limit” of this process produces a very interesting picture, as can be seen below.
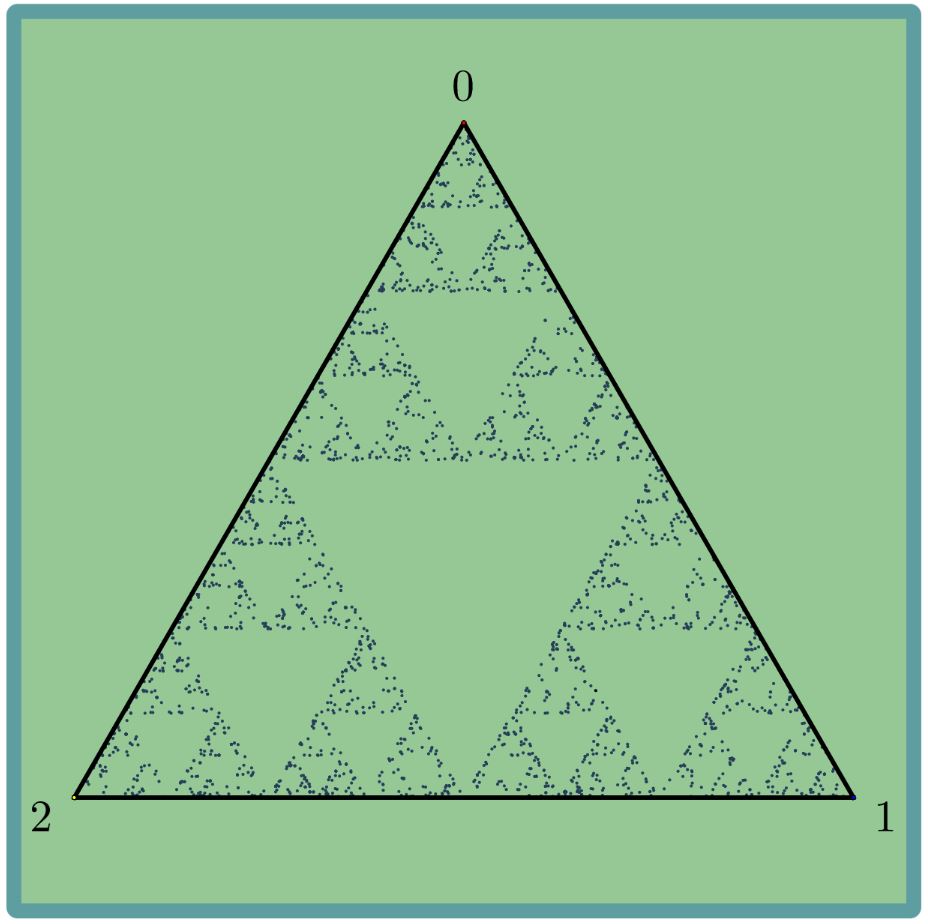
This process is called a random walk, since at each step we choose one of the vertices at random and continue according to this choice.
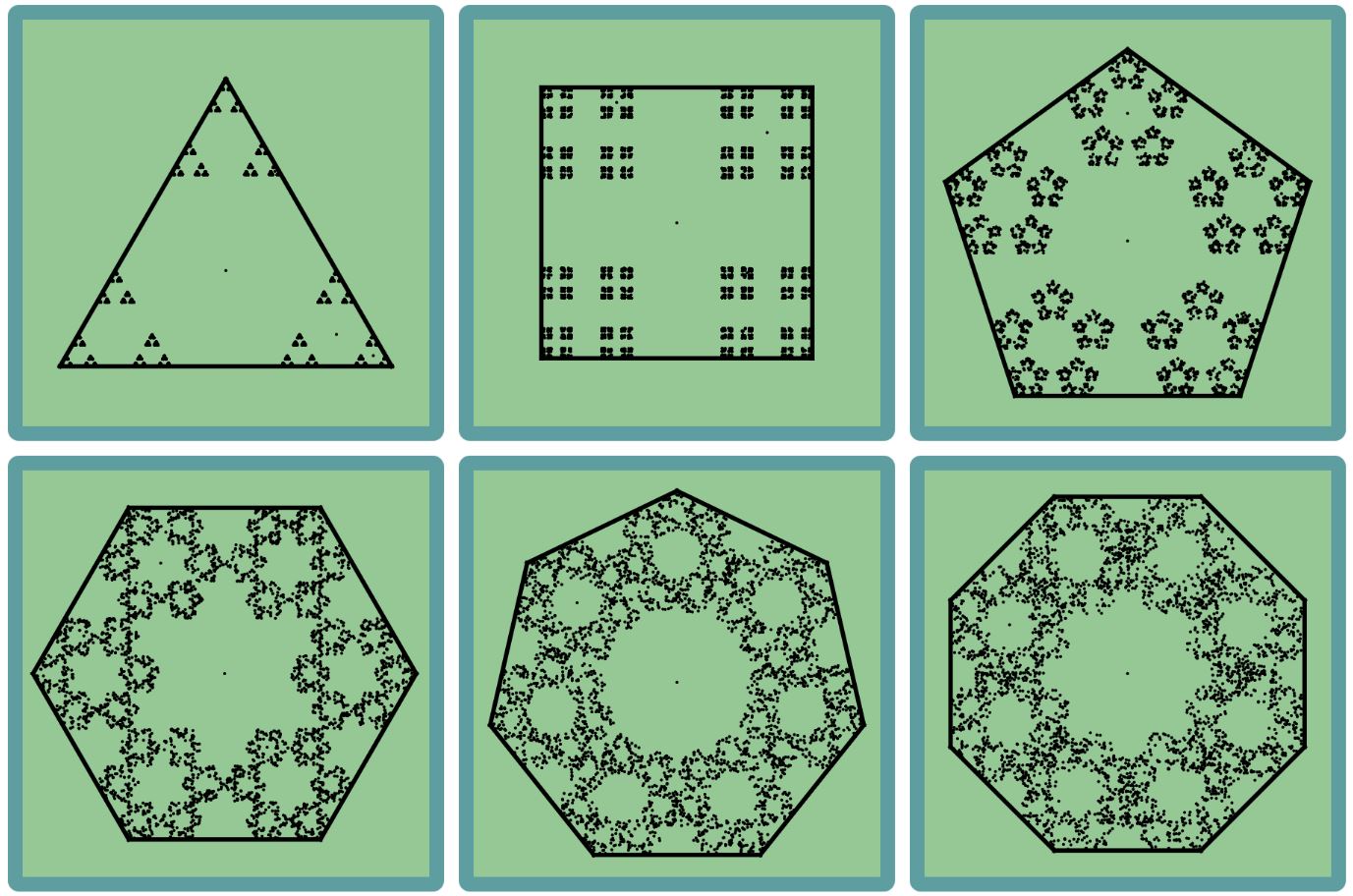
An interesting and natural question is if we can create more interesting pictures by starting with a different shape. For example, here are the result of the same process, but starting with a square and pentagon.

For the square, it seems like we just have a uniform distribution of points. For the pentagon the picture is not that simple – some places are empty (e.g. the center), while some are quite full.
To better understand this process, instead of going half the way towards the vertices, we can use a different ratio. For example, if we move 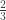
For 

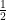


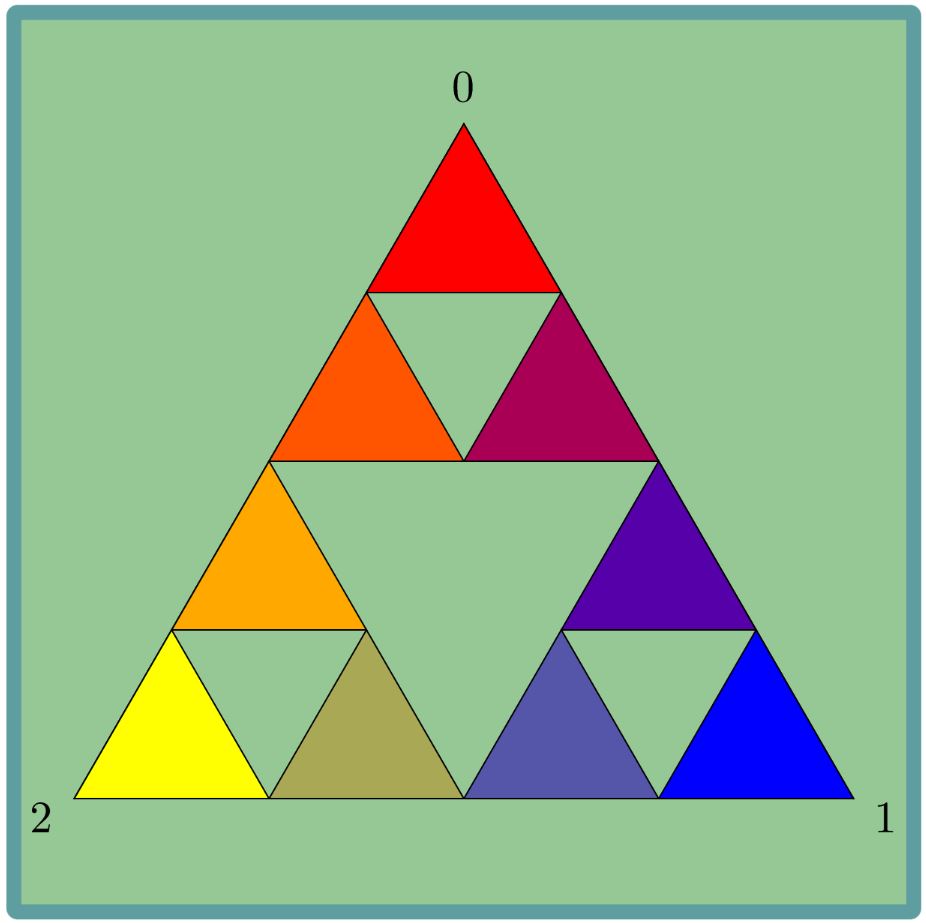
On the other hand, we can rearrange the vertices a little different, still with ratio 2/3, and get an interesting picture like in the triangle.

What we will try to do in this notes is to understand some of the mathematics behind these random walks and the final images that we get.
2. The Sierpinski Triangle
In this section we will concentrate on the process with ratio 1/2 when we start with the triangle. In this case the final image is called the Sierpinski triangle. In this section we will try to show that the only image possible (more or less) for this walk is the Sierpinski triangle

Before we start, recall that we have the following notation:
- The points we get in this process are denoted by
.
- Denote the three vertices of the triangle by
and
.
- Denote the choices of the vertices by
for
.
Note that moving towards a point 


In particular, in our case, the maps describing moving half the way towards the vertices are
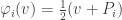
2.1. Simplifying the problem
As with many difficult problems in mathematics, and in general, the first step should be to try and simplify them as best as possible. Once we solve a simple version of the problem, we can hope to (1) get some intuition about the general solution and (2) use the simple result and extend it to get the full result.
In our case, instead of considering infinitely many steps simultaneously, let us consider just the first step, namely what can we say about

Can we show it directly from the process definition? Yes, but before we prove that let us consider a very special case – suppose that we chose 




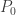
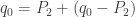


namely we start at

This is of course true if we chose 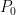

Corollary:
The function 


Now the claim is clear. If we start with a triangle and shrink it by a factor of 2 towards one of its vertices, than we get a times 2 small triangle near the corresponding vertex.
We now know that the point 
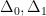




2.2. A partial result
Now that we have a very simple observation, let us study it and try to prove some partial result which will hopefully lead to the proof of our original result.
Under our simplified problem, we can only ask for each 
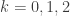
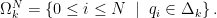
Running a simulation we can see that 
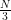

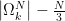


This claim about the orbit of our point is of course not always true. If for some reason we keep choosing only the bottom left vertex, then all of the point (except maybe the first which we ignore) will be in 
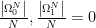


Remark:
Notice the difference between what we know and what we claim. We know that in each step we choose uniformly at random, namely with probability 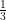
Let us give a proper formulation of this claim.
We begin by denoting the choice of indices for our vectors by 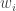

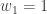


Lemma:
For each 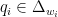
We can now write 

This is a much better definition for 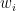
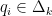

Claim:
For every 

This claim should be understood as follows: there are many ways to choose our vertices in each step, but out side of a very small collection of bad choices, we are always spending 
The experienced probabilists will immediately see that there is another way to formulate this limit which will follow from the well known (and elementary!) weak law of large numbers. The main trick here to think of 
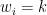
Let us fix 
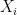

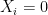



Thus, in the claim above we want to prove that

The term 
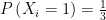

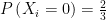

The weak law of large numbers say that if the 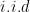

Theorem (Weak Law of Large Numbers):
Let 

2.3. Improving the partial result
What we did so far is:
- We tried to simplify our problem by ignoring the “infinitely many points” and only consider the first two point.
- This led us to consider the 3 small contractions of the original triangle.
- Restricting our attention only to these triangles, we conjectured that the orbit of the point spend around
- We got a little bit into the details of this claim and added the “with high probability” part.
- Finally, we showed that our simplified conjecture follows from the Weak Law of Large Numbers.
Now we can try to repeat this proof process but with a little bit more information. Considering the first 3 points, we can show that the third point must be in one of nine very small triangles, depending on the first 2 choices of vertices:
As before, we can again ask how many times we visit each triangle, and a simulation will show that we spend around 
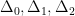

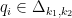
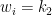

Lemma:
For all 

Continuing to follow the previous step, let us fix 
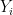

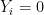

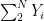

where as before

Unfortunately, we cannot use directly the Weak Law of Large Numbers, since the 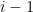
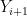



Recall that we can “measure” how much two random variables are dependent by computing their covariance

and in particular 

In our case 



In order to generalize the Weak Law of Large Numbers, let us first recall its proof using Chebyshev’s inequality.
Theorem (Chebyshev’s inequality):
Let 


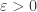

This already looks similar to the weak law. Just put 

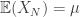
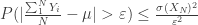
If we can only show that 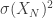
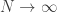

In the case where the 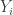




To conclude, we can keep subdivide our triangles, each one to 4 smaller triangles, and remove the middle one, and for each such configuration the orbits of our point will spend (up to some
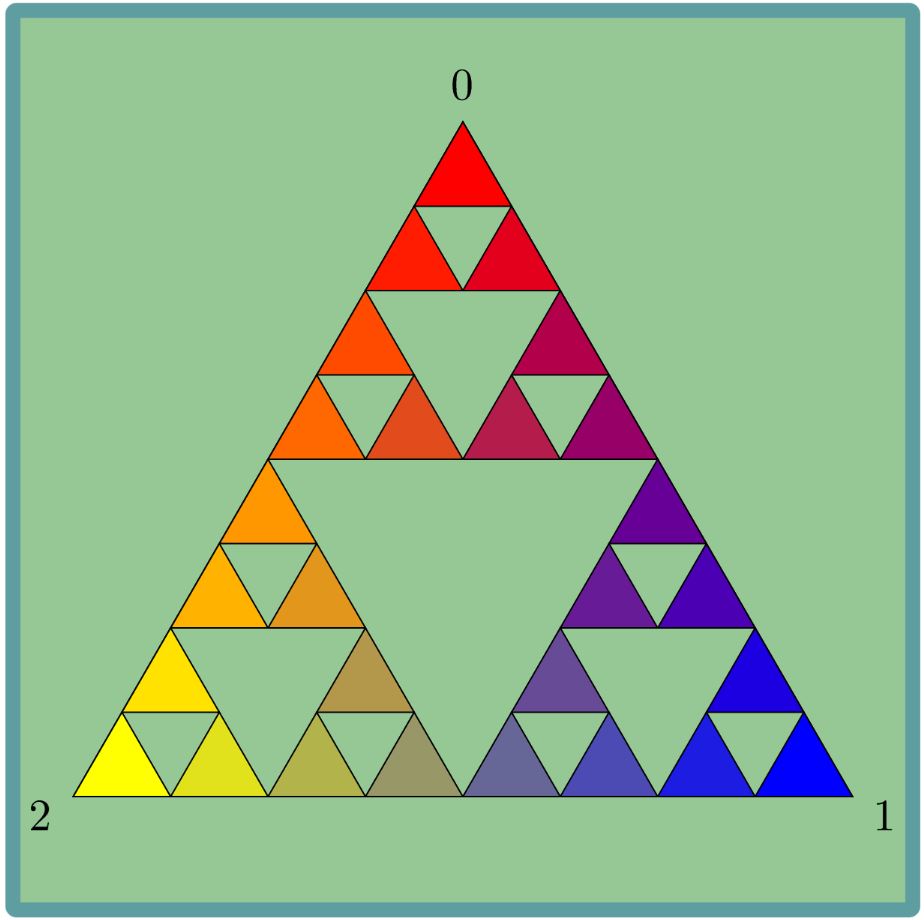

So now we know that if we fix a triangle size, the orbit spends the same amount of time in each triangle. The only shape that has this property is the Sierpinski triangle, so whatever the definition of “limits of random walks” is, the limit here should be the Sierpinski triangle.
2. The other examples
We saw that the random walk process implied that “its limit” should be “equality distributed” in our first three colored triangles, and then after the second step in the nine smaller triangles, then 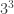

The square is a disjoint union of four smaller (by a factor of 2) squares near its vertices. Thus, just like the Sierpinski triangle, it must be the limit of our random process with 4 vertices.

On the other hand, for the pentagon, the 5 contractions are not disjoint, so we do not expect a “simple” picture as in the case of the triangle and square. Note how there seem to be more points where the smaller pentagons overlap.

When we switched to ratio 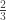


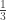 of the hexagon
of the hexagonFinally, when we rearranged the 8 vertices in a square shape, it corresponded to 8 disjoint contractions of a square, thus giving us a final image with smaller and smaller squares, very similar to what we got in the Sierpinski triangle.

All the images that we saw so far are call “self similar sets”, since they are similar to themselves after the corresponding contractions. You can now try running your own simulations with random walk and see what images you can come up with. In particular, when you start with a “nice” shape and where the contractions produce disjoint sets, the final image usually seem more interesting. In general these processes usually use more general map and not just contractions, and in particular they use translations and rotations. In a future post, where we will ask what is exactly the limit of a random process, we will discuss this more general setting.
