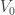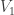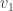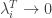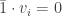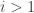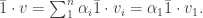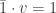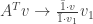Imagine going to a new amusement park for the first time. Once you get there, you go to the first ride that you see, and when you finish it, you randomly choose one of the roads leaving it and follow it until you reach another ride. You continue like this for a long time – every time you go on a ride, then choose a random road (might even go back on the same road that you came) and walk on it until you reach your next ride.
After doing this for a long enough time, on which ride would you go on the most? Go on the least? And how are these questions connected to eigenvectors and eigenvalues?
People randomly enjoying themselves in an amusement park.
In order to get some intuition about this problem, let’s consider some simple examples.
The simplest case is when there is only one ride, but then there is really nothing to prove. After that, we might have two rides connected by a road. In this case you will just alternate between the two rides, and you will get stuck like this for the rest of eternity.
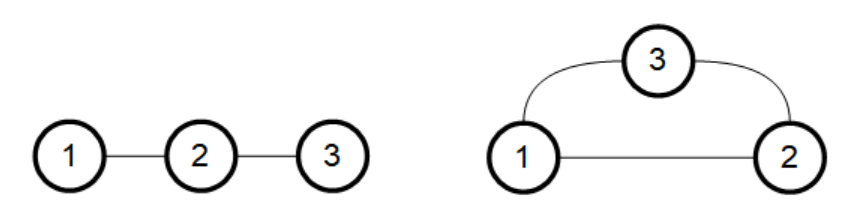
We now go to the first nontrivial case – there are 3 rides in the park. We may assume that all the rides in the park are connected by roads, since otherwise there will be rides that we can never reach, and this is just cruelty. So under this assumption we have two options – either each two rides are directly connected by a road, or we have one ride which is connected to the other two, which are not directly connected.
A not amusing presentation of two amusement parks
Suppose first that we are in the case on the left, where there is no direct road from 1 to 3. It is then easy to see that in our journey through the park, we alternate between being on ride 2 and being on one of the rides in . This means that if we went on rides, then at of the times we were on ride 2. After each time we go on this ride, we go to either ride 1 or ride 3 with equal probability, so we expect to visit each of these rides around times.
In the cycle case on the right, we no longer have this alternation trick like before, but we can still try to adapt the second argument. Suppose that we went times on the three rides, and we set and to be the number of times we went on rides and respectively. If we are on ride 1, then with probability we will next go to ride 2, and otherwise (also with probability ) we will go to ride 3. We can similarly do these arguments for the other rides.
Looking at it from the other way around, if we are now on ride 1, then with equal probabilities () we came from either ride 2 or ride 3. Thus if we know what are and , then we expect to be more or less (assuming, the number of times we visit each ride doesn’t change to much after one such step). The same argument can be said for and so we expect the tuple to “almost” satisfy the equation:
But this equation is none other than asking to find an eigenvector for the matrix above, corresponding to the eigenvalue 1. For this matrix, it is not hard to check that the eigenspace for 1 is spanned by the constant vector . This means, that in our original question, we will visit each ride around the same number of times (because .
This is a good place for a sanity check. In the first graph we had two leaves and one node with two edges, and in a sense we saw this structure in our solution ( visits for the leaves and in the middle node). The second graph was completely symmetric, so in the solution we saw that each node is visited the same amount of time.
The mathematical model:
Now that we have a little bit of intuition, let’s try to build a mathematical model for a general amusement park.
We begin by thinking about the park as a graph, where the vertices are the rides numbered by , and the edges are the connecting roads. We will write if there is an edge from vertex to vertex . As we mentioned before, we may assume that our graph is connected – any two rides are connected (not necessarily directly) via a sequence of roads. Given the -th vertex, we denote by its degree (=number of edges which touch it). This means that when we leave the vertex , we choose one of its edges uniformly to lead us to the next ride, namely, the probability to choose each of these edges is . To visualize this random choice we make our graph into a directed graph, and on each outgoing edge we write the probability of choosing that edge when leaving the vertex:
The probability of choosing an edge leaving vertex is .
Since our system is probabilistic – we keep choosing roads at random – and as such we can only ask probabilistic questions (e.g. which ride\vertex do we expect to visit the most). There are now several ways to think about how the dynamics of our system works.
One way, is instead of having just one person travelling on the graph, we have people doing it where is very large and then follow the quantities of people in each vertex over time, which we measure by . For example, in the graph above vertex 1 is connected to vertices 2 and 3 so that, so if there are people there at time , then at time about will move to each of the vertices 2 and 3.
The second way to view this system, is as above, but instead of counting people in each vertex, we measure their part out of the whole visitors in the park (so we will have instead of just in the previous example). If we denote by how much of all of the people are in vertex at time , then we will get that at each time . In other words, the vector is a probability vector. With this new notation, we can also think about the term as the probability of being in vertex at time . Finally, at time we start in a single vertex, so up to reordering, we may assume that .
Now that we have a presentation of our states at each point in time, we want to find the relation between consecutive times. In order to compute we need to know first all the at time and then ask what is the probability of moving from vertex to vertex . Since we choose edges (=roads) at random, in order for this probability to be nonzero, first we must have an edge connecting these two vertices. Second, our choice of edge leaving vertex is uniform, so we will choose the one leading to vertex with probability , where is the degree of vertex . Then we collect all the probabilities together to get
The equation above tells us that the vector can be computed from in a linear way. More precisely, if we define the matrix to be such that
then we will get that .
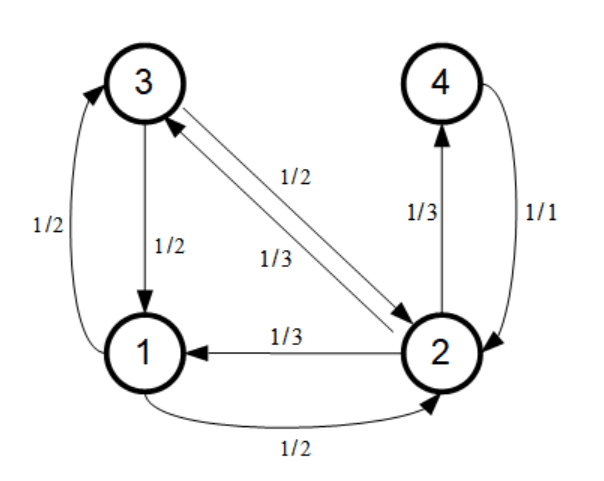
For example, let us return to our two graphs with 3 vertices. In the case of the path , the degrees are and and the matrix will be
So if, for example, we are at the first ride, namely we start at , then next we will be on the second ride . After finishing with this second ride we have that so with probability we will be in either the first ride or the third. Equivalently, we can think of that as having half of the people in the park on ride 1 and half on ride 3.
In the case of the circle, each vertex is connected to the other two vertices, and the matrix will be the one then we saw before:
Eigenvectors and eigenvalues
Now, that we have our mathematical modeling with the equation , we can use induction to conclude that . In our original question we asked which ride we visited the most, which with our new notation becomes for which the value is maximal? Of course, this index depends on . Moreover, as we have seen with the 1-2-3 graph before, this index can alternate depending on whether is even or odd. Actually computing or can be rather hard in general, but luckily for us, linear algebra has exactly the tool to try and solve this problem – eigenvectors and eigenvalues.
Recall that an eigenvector corresponding to an eigenvalue for the matrix is a vector satisfying . For such vector, it is very easy to compute which is simply . More generally, if where are eigenvectors corresponding to eigenvalues , then . Finally, we say that is diagonalizable if it has some basis of eigenvectors, in which case we can use the argument above for every vector. In particular, we could use this to find what is .
Finding the eigenvalues is usually done by finding the roots of the characteristic polynomial, which is not an easy task in general. However, our matrix is not any general matrix – it comes from a graph. To visualize what is an eigenvector we attach each to the corresponding -th vertex, and then simply says that for each we have that is the “average” of the entering it from neighboring vertices. However, this is not the standard average – the weight that we attach to each is the weight that we have on the corresponding edge it moves on.
For example in the graph above, should be equal to (blue arrows), while (red arrows).
In order to really be an average, the sum of the weights should be one, which is not the case. However, if instead of looking on edges entering the vertex, we look on edges leaving the vertex, we would instead get that and similarly , which is the uniform average over the neighbors. In our matrix notation, inverting the direction of the edges is the same as transposing the matrix (check it!), and what is nice about taking the transpose, is that and have the same eigenvalues (this is because transposing a matrix doesn’t change the determinant). Thus, just to find the eigenvalues, we can consider this problem instead – look for a vector and such that for each , we have that is the uniform average of the with .
Stochastic matrices:
Taking the constant vector , we immediately see that it corresponds to the eigenvalue 1. Indeed, the number 1 is always the average of 1’s! In matrix notation we get that . Matrices which satisfy this condition are called (left) stochastic matrices. This condition already tells us that 1 is an eigenvalue (from the right) of our matrix also. The eigenvectors of and are usually different, though once we have the eigenvalue 1, finding an eigenvector is a simple problem of solving linear equations, e.g. , which we all know and love, so this will not be a problem.
What about other eigenvalues? Using our new point of view which uses uniform averages, we can apply a new method – if a number is an average of , then it cannot be strictly larger (resp. smaller) than all of these . More specifically, suppose that is an eigenvector for an eigenvalue and suppose that is the maximum in absolute value. Then we will get that
and in particular we conclude that . Thus, not only 1 is an eigenvalue, all the rest of the eigenvalues are smaller in absolute value. Let us show a little bit stronger result.
Suppose that we find some eigenvector with . This means that both of the inequalities above must be equalities. From the equality in the triangle inequality we get that the with must have the same sign, and from the second inequality they must also satisfy . In particular this means that the neighbors of the -th vertex also have maximal absolute value for , so we can apply the same argument for them and their neighbors. Repeating this process as many times as we need, and using the fact that our graph is connected, we conclude that all the are the same.
Of course, if the vector is constant, then its entries in absolute values are also constant, but is this the only solution? The answer for this is false, and indeed the vector is an eigenvector of the eigenvalue -1 for the following graph:
The red are the entries from the eigenvector
The graph above is bipartite – we can separate the vertices to two sides (according to the sign of , namely and ) and there are no edges between two vertices which are either both in or both in . This means that when we travel the graph, we alternate between the two sides of the graph (just like in the graph from before). I will leave it as an exercise to show that a similar result holds in general – the matrix has eigenvalue -1 if and only if its graph is bipartite, and then the signs of the entries of the eigenvector correspond to the two sets in the decomposition of the vertices.
For clarity of this exposition, we will ignore these bipartite graphs, which means that our graph has some cycle of odd length. Note that this will always be the case, if we also let the people stay on the same ride, because then we will have self loops which have length 1. Anyway, if the graph is not bipartite, then we have just seen that 1 is an eigenvalue, and the rest of the eigenvalues are strictly smaller in absolute values. Moreover, the eigenvectors of the eigenvalue 1 are just the constant vectors. In the linear algebra notation, this means that the geometric multiplicity of the eigenvalue 1 is 1.
Up until now we used the fact that the sum of the weights leaving each vertex sum up to 1 (though we didn’t really need them to be equal!). If you paid enough attention, you also saw that in our triangle inequality argument we also used the fact that these weights are nonnegative. Matrices with nonnegative entries play crucial roles in many problems, and the result above can be generalized to such matrices. This result is known as the Perron Frobenius theorem. In our case, among other things, this theorem shows that not only the geometric multiplicity of 1 is 1, but also its algebraic multiplicity is 1, or in other words 1 is a simple root of the characteristic polynomial of .
As mentioned before, the eigenvalues of and are the same, so also has 1 as its eigenvalue and the rest of its eigenvalues have strictly smaller absolute values. Actually, one can show that transposing the matrix doesn’t change the multiplicities, both algebraic and geometric, of the eigenvalues, so 1 is a simple eigenvalue of also.
Back to dynamics:
Let us denote by the unique eigenvector (up to a scalar multiplication) of corresponding to . Assume that is actually diagonalizable, and let be eigenvectors for the eigenvalues such that is a basis for . If is any vector, then we can write it as . We then get that
Using the fact that we get that as . Thus, for all big enough we have that is up to a small error which goes to zero as . In other words, up to this small error we know what is for all big enough , which is exactly what we wanted to know. Moreover, we didn’t even needed to find the rest of the eigenvalues and their eigenvectors! Well, almost. We still need to find what is . Fortunately, there is a nice trick when dealing with eigenvectors of a matrix if we know the eigenvectors of it transpose.
Lemma: If satisfy , with , then .
Proof: Consider the scalar . Using our assumption we get that
Since we conclude that we must have that .
Returning to our matrix coming from the graph, we already computed which is the eigenvector for 1, and we assumed that there are eigenvectors corresponding to eigenvalues which are not 1. On the other hand, we know that satisfies (so it is an eigenvector for ). It follows that for all . Thus, if , then
If we know that , then both of and are nonzero, and we get that . Recall that in our original problem, the vector is , so that .
To summarize, we get that
Theorem: As we get that
.
Note that while the proof for the theorem above was not trivial, in order to apply it, we only need to know what is , and in order to find it we only need to know how to solve a simple system of linear equations , or equivalently .
The last result followed from the fact that our matrix was stochastic, and can be interpreted in a probabilistic language. Indeed, we defined our process so that each of the will be probability vectors (their entries are nonnegative and sum up to 1) so the same is true for the limit. Hence, we just need to choose to normalize so its entries will sum up to 1 (or more generally, sum up to the same sum of the entries of ). The algebraic reason for this follows from the fact that and has nonnegative entries. Indeed, if is a probability vector, then the entries of are nonnegative and , so that is also a probability vector.
This almost completes the proof, however we did assume along the way that is diagonalizable. The result above still holds if this is not true, but for that we need some more tools, e.g. the Jordan form of a matrix, and I will leave it for another time. I will just mention that if our graph is -regular, namely all the degrees in the graph are the same and equal to , then the matrix is symmetric. In this case it is true that it is diagonalizable, and moreover it has a base of eigenvectors which form an orthonormal base. This result is usually known as the Spectral Theorem.
Some more applications and conclusion
The problem of the amusement park is quite similar to many other “real life” problems. For example we can consider people surfing the web by going from site to site by clicking links “randomly” in each site. Here too we can ask which site do we expect them to visit the most, thus in a way “defining” what is a popular website.
Similarly, we can think of a system of players (=vertices), such that on each turn they pay a certain percentage of their money to other players (=weights on the edges). The same model will help here as well, though we will probably want to add self loops, so players can keep some of their money each turn. We can then ask which player will have most of the money after long enough time.
There are many more such problems, and I encourage you to find some by yourself. Mathematically speaking, we combined the fields of linear algebra, combinatorics and probability to get some interesting results. The next step after this is to work with more “symmetric” systems where the random choices have some structure by themselves. Probably one of the most famous problem is mixing a deck of card, where at each time you choose one of a small set of types of deck mixing (e.g. switch the first and second card, put the top card at the bottom of the deck , etc.). This type of problems usually add to the mix the field of abstract algebra and in particular groups and their representations, and at least for me, this combination is one of the most beautiful parts of mathematics.



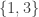










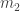
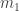
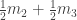






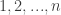



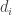

 .
.
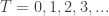


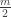
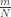
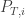
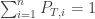
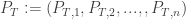
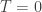


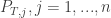


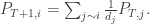

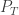


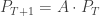
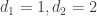








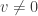







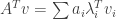


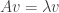

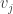

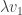

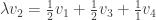
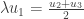




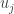


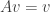

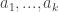


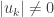




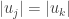




 are the entries from the eigenvector
are the entries from the eigenvector