
Taking a final exam in a course is not really a celebration cause for most students, but it is just not as fun to be on the other side as exam checkers. It can easily take several days to grade the answers for the same question for hundreds of students. The exam checkers would probably tell you that by just reading a few lines from the answer they know if it is going to be (mostly) correct or not, however they still need to read all of it just to be sure. These couple of lines can still be misleading – a good start can still lead to a complete failure, and a bad start might eventually, somehow, get most of the details right.
So maybe when checking exams we cannot really do it, but are there problems where reading only few lines from a proof is enough to determine its correctness? As it turns out, certain problems have innate structures that makes them more “stable” than others – if you write a “wrong” solution for them, then you can see it almost everywhere, so reading just a few lines will be enough.
One of the best examples for this kind of problem is the linearity testing. Suppose that someone claims that a function 
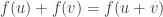
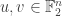
Probabilistic proofs
As it is usually the case, our story starts with the famous linearity testers – Alice and Bob. Bob has a function 
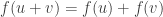
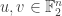
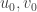

Of course, if 

Suppose Bob actually computed a linear function 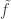
The question becomes interesting when Bob doesn’t really start from a linear function, and his function 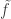
This miracle property is called the Soundness of the problem. Let’s give a more formal definition.
Definition: Given two functions
, we define their Hadamard distance by
. In other words,
measure the chance of choosing a vector on which
disagree, and in particular
if and only if
.
For a set
of functions, we write
.
With this definition, we want to show that following:
Theorem: Let
the set of linear functions. Then for any
, the probability
is at least
.
In other words, if 
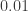
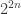
From simple to complicated
Many times, when facing a new problem, one of the biggest road blocks is where to start analyzing it. One of the approaches that I have found useful over the years, is trying to start with a more simplified version to get some intuition and after that add the structure back until returning to the original problem. This can be done, for example, by looking at a specific simple case of the problem, or, as I will do here, simplify the language that we use to study it.
Set Theory
In mathematics, one of the most simplest of languages is that of set theory. In this world of sets, and in particular of finite sets, the first question we should try to answer is what is the size of the sets. Our problem contains two sets – the set of all functions, and the linear functions
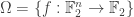

Let us start with studying 

In general, determining the size of sets is not an easy task. However, in our case the set 
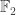



Algebra
After set theory, the next language we should use is the one of linear algebra. While it can be very technical at times, it is quite easy to work with (and there is a reason that it is usually studied at the first semester). Our three sets from above, 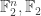


Symmetry and Geometry
Next in our journey, we will look for all sorts of symmetries that our objects have. To get some intuition and be able to visualize the objects, lets restrict our problem to the 

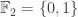


The importance of this visualization is that these sets have a lot of interesting natural symmetries like the rotations or reflections of the square, and these are closely connected to our objects.
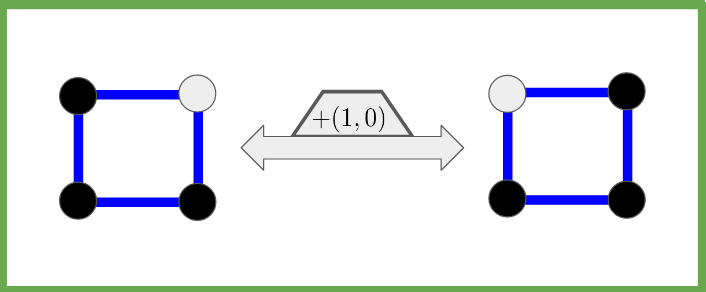
Since our sets are actually vector spaces, they come with the natural addition operations which act on them. For example, in our black\white visualization of the set 

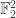
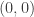
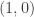
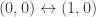


Similarly, adding 

Once we have these symmetries on
This is already a lot of interesting information, and we haven’t even started to look at the linear functions. The hope is that we can use each of these worlds of set theory, algebra and symmetry on these linear functions and combine it with what we saw on this larger set of all binary functions to produce some interesting results.
Describing the linear functions
Set theory of Linear functions
The set of linear function is defined by the linearity condition, namely

Unlike the set of all functions, we cannot easily use this presentation to find the size of this set. However, this definition of linear function is not random, and it is rooted deeply within the algebraic structures of all of our sets. In particular, one of the first results that we learn on such functions, is that linear functions are determined completely by their values on a given basis of the vector space. Alternatively, every function from a basis can be extended uniquely to a linear function. Putting it more formally, if 

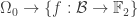
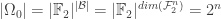
Algebra of Linear functions
The size of 
The symmetries of Linear functions
Returning to our 

What happens if we apply our reflections and rotation on these linear functions? No matter what we do to the full white square (the trivial function) it remains in place. However, if we apply them to the second colored square, the up-to-down reflection keeps it in place, but the left-to-right reflection and the 180 degrees rotation do not. But not all is lost – these two transformations are the same as simply switching the colors (which is the symmetry which comes from the addition in
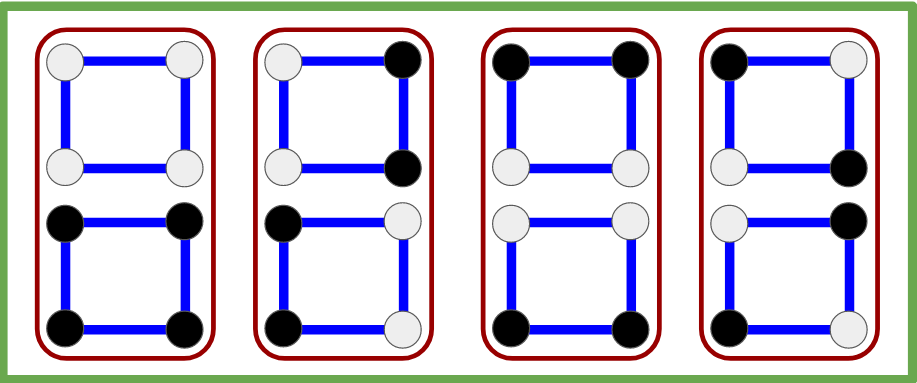
In mathematics, when we have some action on a set, as above, and an element doesn’t change under this action (like the black\white square), we say that it is invariant under this action. The nontrivial linear functions are not invariant, but they are really close – they are invariant up to the color change. These “almost invariant” elements tend to appear in many places in mathematics, from simple examples like these rotating squares to the most advanced parts of mathematics.
If you are reading this post, then there is a good chance you already know some of these “almost invariant” objects really well. Indeed, maybe the best example for this behavior is when a linear transformation 



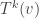


The eigenvectos
In our problem, the posible eigenvalues are 
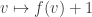
Instead of working with 
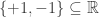


both of which are contained in the 

of dimension 

Definition: For
, define the linear transformation
by
.
Claim: For any
, and a multiplicative linear function
we have that
– namely
.
Proof: Follows immediately from
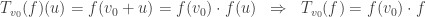
Now we are at a point where we have a set
Orthogonality
To prove that 
We already mentioned that these colored squares are almost invariant, but there is actually an even simpler property that we can see. The number of black and white vertices is always even, and while in the trivial function all the vertices are white, in the rest the number of black vertices equals to the number of white vertices. Now, after we moved to the 


What can we say about such vectors? For 

The two vectors representing the functions have the same length, but more importantly they are orthogonal to each other. If we can show that in general the linear functions form an orthogonal set, then we automatically get that they are independent, and since it is a set of the size of the dimension of our vector space, they must form a basis.
As we shall see soon, “moving” from one linear function 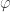


Orthogonality formalization
To prove this claim, we start with the definition of our inner product.
Definition: For two functions
we define their inner product as
.
With this definition in mind, lets see what we can say about functions from 

The first immediate result is that 




The inner product 


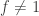
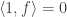
Claim: Let
be any two functions. Then
1.
, and
2. If both functions are multiplicative linear, then

Corollary: The set of multiplicative linear functions
and therefore forms a basis.
Back to linearity testing
Now that we have all this new information about binary functions and linear functions we can return to the original problem of linear testing.
In the original problem, we wanted to show that if a binary function 

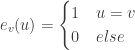
we think of 
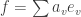


Combination of the standard basis’ elements where 1=white, 0=green and -1=black.
Note that this basis is almost orthonormal – its elements are perpendicular to one another, and all have length 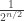

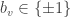
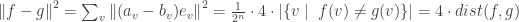
Similarly in the linearity condition, is “defined” using this basis, since we look at the coefficient of 

However, we just saw that there is another basis, which consists of linear functions, so we can write our function as a combination of these vectors:
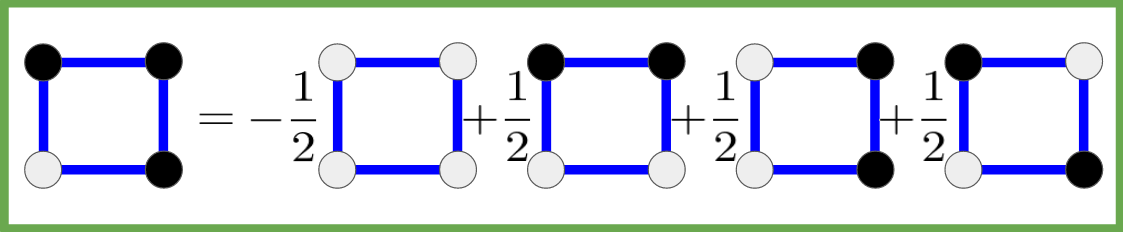
Lets denote these linear functions by 
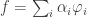

It follows that if the function 

In other words, saying that the a function is far from all of the linear functions, is exactly saying that the 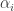

We already see that in this new basis our distance function has a much simpler interpretation, and the main difficulty is to move from one base to the other, though this becomes simple if we can describe our expressions using inner products.
What about the probability for Alice to reject the function? If we can somehow rewrite it using the language of the inner product, we could move to this basis as well, and in this basis all the functions are linear, so it would be a much easier place to work in. And indeed we can rewrite it in the new basis and get that Alice will reject the function with probability at least 
The linearity condition
We would like to count how many pairs will lead Alice to reject the function. For a single 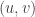

so we want to sum over these expressions. Then the probability to reject will be

The term in the sum looks similar to an inner product, but has three factors instead of two, and have a double summation instead of a simple summation. As it turns out, this is because we have in a sense two inner products. First, we can define 

We would much prefer to work with the coefficients of 
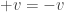

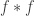


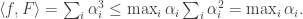
This means that the probability for Alice to reject is

which is exactly what we wanted to show.
In conclusion: So what did we do?
Trying to analyze our problem, we looked for simple ways to describe its objects. We started with considering them as sets, then added the addition to get algebraic objects, and then used these addition operations to find symmetries and actions on our sets. When applying the same process to the linear functions, we concluded that they are also orthonormal eigenvectors which led us to a new interesting basis.
Then the main trick was moving from one basis to the other. The standard basis is what we usually work with, and it is easy to describe the problem in this basis (for example, the distance is measured by simply counting the number of different coefficients). However, the second basis is far more related to the essence of the problem – it is exactly the set of linear functions. Both bases were orthonormal (up to a uniform normalization), so when the expressions were transformed to use inner products, it was very easy to move from one to the other. Once we moved all of our notation to this new basis, the problem became almost trivial.
Along the way we also encountered the convolution operation, which behaved nicely with respect to this base change. You might have seen this sort of behavior in another place – the Fourier transform. This is not surprising, since this base change is the Fourier transform, and this interesting result about the convolution is one of the main reasons that the Fourier transform is so important.
All of these different structures, the bases, and the conversion between them were miraculously combined together to show that if Bob didn’t really make an effort to create a linear function, then Alice would have a good chance to detect it. It does, however, rely on the fact that Bob is honest. If Alice asked Bob for the values of 




As a final thought, I would like to point out that this miracle combination happens a lot. After all, it is the basis for the Fourier transform that every engineer knows by heart, or its mathematical name – group representation. This in itself is a subject on its own, but once you understand its basics, results like those in this post become much more natural.
